
From Chaos to Control: Mastering LLM Outputs with LangChain & Pydantic
This practical guide shows developers how to implement type safety and automatic validation, turning unpredictable language model responses into production-ready Python objects.
1. Introduction
Working with Large Language Models (LLMs) like GPT-4 can feel like trying to have a conversation with a brilliant but sometimes chaotic professor. While they provide incredibly sophisticated responses, the free-form nature of these outputs can be a developer's nightmare when building production applications. How do you reliably extract specific fields? What happens when the format changes unexpectedly? How can you ensure the data types match your application's requirements? Enter the powerful combination of LangChain and Pydantic - a duo that brings structure and reliability to the wild world of LLM outputs. In this tutorial, we'll explore how to transform unpredictable LLM responses into strongly-typed, validated data structures that seamlessly integrate with your Python applications.
💡 Looking for the code? You can find all the code examples from this article in this GitHub Gist.
2. The Power of Structured Outputs
Working with raw LLM outputs is like trying to parse a JSON string that's been written by a human - it might look right at first glance, but it's prone to inconsistencies and errors. Here's what typically goes wrong:
1. Inconsistent Formatting #
- One response might return a list as "1, 2, 3"
- Another might return it as "[1,2,3]"
- And yet another as "1\n2\n3"
2. Error-Prone Parsing #
- String manipulation to extract fields
- Regular expressions that break with slight variations
- Manual type conversion and validation
3. Integration Headaches #
- No type hints for your IDE
- Runtime errors when formats don't match
- Difficulty maintaining code that depends on output format
By using structured outputs with Pydantic models, we transform this chaos into order:
- Type Safety: Every field has a defined type that's checked at runtime
- Automatic Validation: Values are validated against your rules before they reach your application code
- IDE Support: Full autocomplete and type hints for your structured data
- Clear Contract: The model serves as documentation for what data to expect
- Easy Integration: Direct compatibility with FastAPI, SQLAlchemy, and other modern Python tools
Think of it like having a strict but helpful assistant that ensures every piece of data from your LLM fits exactly where it should in your application. Let's see how to build this in practice...
2.1 The Perils of DIY JSON Parsing with LLMs#
Let's start with a common approach many developers take when first working with LLMs - asking for JSON directly in the prompt:
def get_raw_json_prompt(review: str) -> str:
return f"""
Analyze this product review and return a JSON with fields:
- sentiment (string)
- pros (list of strings)
- cons (list of strings)
Review: "{review}"
Return only the JSON, no other text.
"""While this might seem to work at first, it's a fragile solution. Some days you'll get perfectly formatted JSON:
{
"sentiment": "positive",
"pros": ["Great battery", "Fast performance"],
"cons": ["Expensive", "Heavy"]
}But other times, you might get:
Here's the analysis:
{sentiment: "positive", pros: ["Great battery", "Fast performance"], cons: ["Expensive", "Heavy"]}
Or even:
The sentiment is positive
Pros:
- Great battery
- Fast performance
Cons:
- Expensive
- HeavyAs your needs grow, you might try to get more sophisticated with your JSON structure:
def get_complex_json_prompt(review: str) -> str:
return f"""
Analyze this product review and return a JSON with the following structure:
{{
"overall_sentiment": "string (positive/negative/mixed)",
"summary": "brief summary string",
"main_pros": ["list", "of", "strings"],
"main_cons": ["list", "of", "strings"],
"aspects": [
{{
"aspect": "specific feature or aspect name",
"sentiment": "positive/negative/neutral",
"confidence": "float between 0 and 1",
"relevant_text": "quoted text from review that supports this"
}}
]
}}
...
"""Now we're really in trouble. Not only do we have all the previous problems, but we also have to deal with:
- Nested structures that might be malformed
- Type mismatches (getting strings instead of floats for confidence scores)
- Missing fields in nested objects
- Inconsistent field names
- No type hints for your IDE
- Complex error handling
2.2 Enter Pydantic: Your Type Safety Savior#
Instead of fighting with JSON parsing, let's define our expectations clearly with Pydantic models:
from pydantic import BaseModel, Field
from typing import List
class SentimentAspect(BaseModel):
aspect: str = Field(description="The specific aspect being discussed (e.g., durability, ease of use)")
sentiment: str = Field(description="The sentiment (positive/negative/neutral)")
confidence: float = Field(description="Confidence score between 0 and 1")
relevant_text: str = Field(description="The specific text that supports this analysis")
class ReviewAnalysis(BaseModel):
overall_sentiment: str = Field(description="Overall sentiment of the review")
aspects: List[SentimentAspect] = Field(description="List of analyzed aspects")
main_pros: List[str] = Field(description="Main positive points")
main_cons: List[str] = Field(description="Main negative points")
summary: str = Field(description="Brief summary of the review")This approach gives us:
1. Type Safety: Each field has a defined type that's validated automatically
# This will fail if confidence isn't a float between 0 and 1
aspect = SentimentAspect(
aspect="battery",
sentiment="positive",
confidence="not a number",# TypeError!
relevant_text="Great battery life"
2. Clear Contract: The model serves as documentation and a schema
# Your IDE will know exactly what fields are available
analysis = ReviewAnalysis(...)
print(analysis.overall_sentiment)# Auto-complete works!3. Validation Out of the Box: Pydantic handles all the edge cases
# Missing fields? Pydantic will tell you exactly what's wrong
# Wrong types? You'll get clear error messages# Nested structures? No problem!
4. Integration Ready: The models work seamlessly with modern Python tools
# Works great with FastAPI
@app.post("/analyze")
def analyze(review: ReviewAnalysis):
return review
# Easy database integration
review_dict = analysis.dict()# Convert to dict for storageWhen combined with LangChain's output parsers, this approach ensures your LLM outputs will always match your application's expectations. No more crossing your fingers hoping the JSON is valid - you get guaranteed structure every time.
3. Understanding How Pydantic Shapes Your Prompts
When working with LLMs, getting the output format right is crucial. Let's look at how Pydantic models influence the actual prompt that gets sent to the model.
Remember our Pydantic models? Here's how they get transformed into instructions for the LLM:
- Model Definition: We start with our Pydantic models that define the structure we want
- Schema Generation: The LangChain parser takes these models and automatically generates a JSON schema that gets inserted into your prompt.
- Integration with Prompts: When we use the pipe syntax:
prompt = PromptTemplate(
template="""
You are an expert product review analyzer. Analyze the following review in detail.
Break down each major aspect mentioned and provide a thorough analysis.
Review: {review}
{format_instructions}
Analyze the review following the exact format specified above.
Make sure to identify distinct aspects and provide specific evidence from the text.
""",
input_variables=["review"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
chain = prompt | llm | parser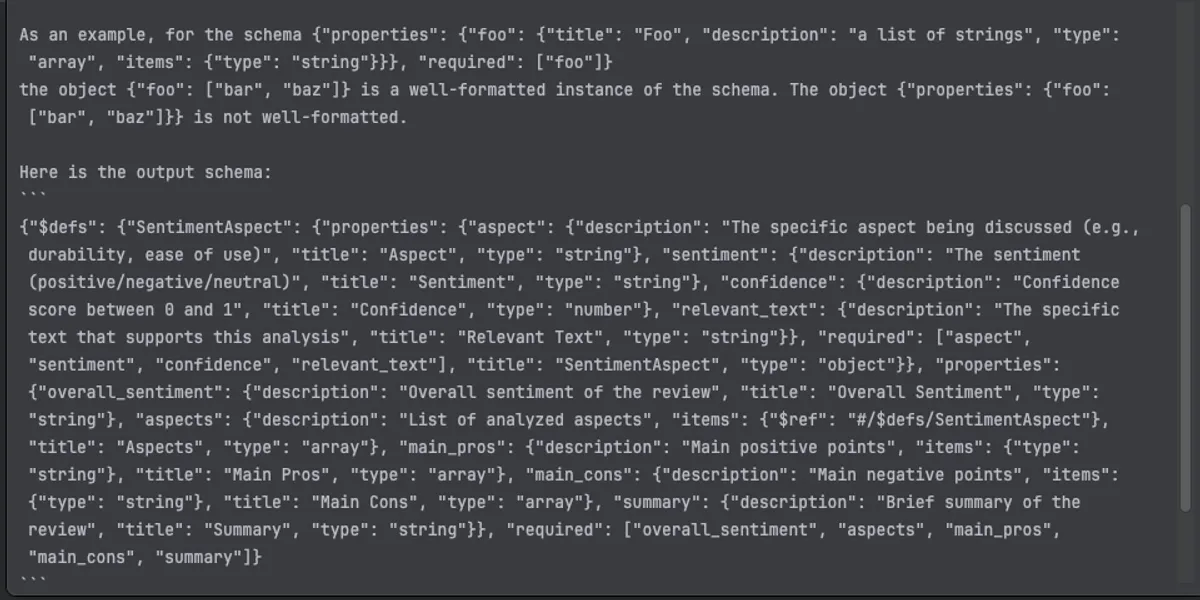
The image shows how our Pydantic models get converted into a detailed JSON schema specification. Notice how each field's description, type, and requirements are preserved and formatted in a way the LLM can understand.
The parser injects these format instructions automatically into your prompt template wherever you use the {format_instructions} placeholder.
Why This Matters:
- The LLM gets precise instructions about the expected output format
- Each field's purpose is clearly defined through descriptions
- Required fields are explicitly marked
- Type constraints are preserved (like confidence being a number between 0 and 1)
- The schema provides a contract that both the LLM and your code understand
This structured approach means you spend less time fighting with output parsing and more time building features. The LLM knows exactly what format to return, and your application gets strongly-typed data it can trust.
Warning Important Note: The effectiveness of structured output heavily depends on the underlying LLM model you're using. While this tutorial demonstrates examples using GPT-4, different models may require different prompting strategies or might have varying capabilities in following structured output instructions.
If you're:
Using a different LLM provider (like Anthropic, Llama, etc.)
Not getting the expected structured outputs
Need more advanced parsing strategies
Want to explore different output formats
Please refer to LangChain's official documentation on structured outputs:
This resource provides model-specific guidance and alternative approaches for handling structured outputs.
3.1 Supercharging Your Models with Examples and Schemas#
While basic Pydantic models work well, we can make them even more powerful by adding examples and extra schema information. This helps the LLM understand exactly what we expect:
class SentimentAspect(BaseModel):
aspect: str = Field(
description="The specific feature or aspect being discussed",
examples=["battery life", "screen quality", "keyboard feel", "performance"]
)
sentiment: str = Field(
description="The sentiment towards this aspect",
examples=["positive", "negative", "neutral"]
)
confidence: float = Field(
description="Confidence score for this sentiment analysis",
examples=[0.95, 0.87, 0.76],
ge=0,# greater than or equal to 0
le=1# less than or equal to 1
)
relevant_text: str = Field(
description="The specific quote from the review that supports this analysis",
examples=[
"battery life is incredible, lasting over 8 hours",
"screen has significant glare issues in sunlight"
]
)
# Complete example of how fields work together
class Config:
json_schema_extra = {
"example": {
"aspect": "battery life",
"sentiment": "positive",
"confidence": 0.95,
"relevant_text": "battery life is incredible, lasting over 8 hours"
}
}
Why Add Examples? #
Field-Level Examples:
aspect: str = Field(
description="The specific feature or aspect being discussed",
examples=["battery life", "screen quality", "keyboard feel"]
)
- Shows valid values for individual fields
- Helps the LLM understand the expected granularity
- Demonstrates the preferred formatting
Complete Object Examples (using json_schema_extra):
class Config:
json_schema_extra = {
"example": {
"aspect": "battery life",
"sentiment": "positive",
"confidence": 0.95,
"relevant_text": "battery life is incredible..."
}
}- Shows how fields relate to each other
- Demonstrates complete, valid objects
- Helps LLM understand the overall structure
When to Use What?#
Use Field Examples When: #
- You want to show valid values for a specific field
- The field has a limited set of possible values
- You want to demonstrate formatting patterns
sentiment: str = Field(
description="The sentiment towards this aspect",
examples=["positive", "negative", "neutral"]# Clear, limited options
)
Use json_schema_extra When:#
- You need to show how fields work together
- The relationships between fields matter
- You want to demonstrate complete, valid objects
class Config:
json_schema_extra = {
"example": {
"overall_sentiment": "positive",
"aspects": [
{
"aspect": "battery life",
"sentiment": "positive",
"confidence": 0.95,
"relevant_text": "battery life is incredible..."
},
# Multiple examples show different scenarios
{
"aspect": "screen quality",
"sentiment": "mixed",
"confidence": 0.85,
"relevant_text": "screen is crisp but has glare..."
}
],
"main_pros": ["Excellent battery life", "Fast performance"],
"main_cons": ["Screen glare issues"],
"summary": "A positive review highlighting battery life..."
}
}
Real-World Impact#
Adding these examples:
- Improves Consistency: The LLM learns your preferred formatting and terminology
- Reduces Errors: Clear examples prevent misunderstandings
- Better First-Time Success: LLM is more likely to get it right the first time
- Clearer Documentation: Your code becomes self-documenting
This becomes especially important in production systems where consistent output format is crucial for downstream processing.
4. Conclusion: Power and Pitfalls of Structured Outputs#
Working with LLMs can feel like trying to have a conversation where both participants speak different languages. Through this tutorial, we've seen how the combination of LangChain and Pydantic brings structure and reliability to these conversations by:
- Converting unpredictable free-form text into strongly-typed Python objects
- Providing clear validation and error handling
- Making our code more maintainable and type-safe
- Enabling better integration with existing systems
Remember that while structured outputs give us more control and reliability, they also add complexity to our prompts. It's a trade-off worth making when you need guaranteed format compliance, but might be overkill for simpler use cases where free-form text would suffice.
The key is to choose the right tool for the job:
- Need strict type safety and validation? Use Pydantic models
- Want simple key-value extraction? Consider simpler parsers
- Building a production system? Structured outputs are your friend
- Just prototyping? Maybe start with basic prompts and add structure as needed
By understanding these patterns and pitfalls, you can build more robust and reliable LLM-powered applications that are easier to maintain and debug.
Happy prompting! 🚀