
RAG system imagined by Midjourney
Evolving beyond simple chatbots: Leveraging RAG systems for more effective Q&A
Learn how to leverage this technology to create intelligent chatbots and support systems that understand and respond using your organisation's knowledge.
🗣️ Audience
- Curious about AI? If you're interested in how Artificial Intelligence is evolving and the potential of Large Language Models (like ChatGPT), RAG systems offer a fascinating glimpse into the future of information retrieval.
- Drowning in data? Do you or your organization struggle to manage vast amounts of information? RAG systems can be a game-changer, helping you unlock the insights hidden within your data by creating intelligent chatbots and support systems.
📖 Glossary
- LLM - Large Language Model ( ChatGPT, GPT-4, Llama 2, Claude 2, Grok)
- Embeddings Model - Deep Learning models used to transform text into numeric vectors
- Vector DB: A database that is specialised in storing and querying numeric vectors
- KNN: K-Nearest Neighbors - A machine learning algorithm used for classification and pattern recognition.
- RAG - Retrieval augmented generation ( A system that can leverage LLMs, Vector DBs and embedding models to create chatbots using your data as a context)
1. Introduction
Remember ChatGPT? This captivating AI took the world by storm with its ability to generate human-quality text. But while it excelled at crafting creative responses, it sometimes struggled with the nitty-gritty of factual information retrieval. This sparked a new wave of research in Large Language Models (LLMs) – after all, what good is a powerful language tool if it can't efficiently find the information it needs to be truly useful?
Enter RAG (Retrieval-Augmented Generation) systems – the next evolution of LLMs. Imagine encountering a customer service team drowning in a sea of questions: "What's your return policy?", "How do I install this software?", "Is your product compatible with mine?". Sifting through mountains of FAQs and manuals feels like searching for a specific grain of sand on a vast beach.
RAG systems are like super-powered FAQ assistants. They leverage the power of LLMs to analyze vast amounts of data, including past interactions, product materials, and FAQs, to pinpoint the most relevant information for each customer inquiry. No more endless document searches – RAG delivers the right answer, fast. This translates to happier customers who get their questions answered quickly and accurately while freeing up customer service teams to tackle more complex issues. Ready to dive deeper into how RAG systems are revolutionizing information retrieval? Let's explore the inner workings of these information retrieval champions!
2. Understanding how RAG systems work
The simplest way to understand this problem is to break it down into 2 pieces:
- Vector DB and Document retrieval/similarity matching ( embedding models)
- Answering questions / Reasoning ( ChatGPT / LLMs)
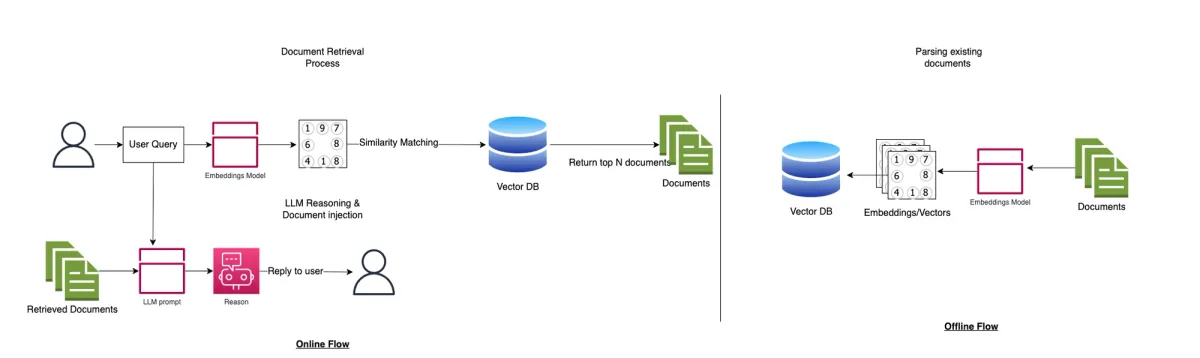
So if you have a lot of data, you parse them using an embedding model and store them in a database. When a user asks a question, this query gets transformed using the embeddings model into vectors with numbers, and using some similarity algorithm, the system identifies the most similar documents.
In the second phase, the RAG system will inject those documents on the ChatGPT’s / LLM prompt and then we rely on the capability to reason. Then the LLM agent will be able to answer the question using the context of information the RAG system has already retrieved.
2.1 The Mighty Vector Database#
Imagine a library with countless books on every topic imaginable. Finding the exact information you need could take hours, right? Here's where RAG systems come in, and the first hero they rely on is the vector database.
Think of a vector database as a special library that stores information in a unique way. Instead of traditional book titles, it uses vectors, which are like fingerprints for information. But how does it create these fingerprints? RAG systems leverage powerful embedding models. These models act like special translators, taking any piece of text (like a sentence or a document) and transforming it into a unique set of numbers – the vector.
This vector captures the essence of the text, considering keywords, synonyms, and the overall context. Just like a fingerprint identifies a specific person, this vector identifies a specific piece of information. It allows the RAG system to quickly find information similar to your query, even if the exact wording doesn't match.
Think of it this way: finding a specific book by title takes time. But finding a fingerprint match is much faster. That's the power of the vector database – it helps RAG systems navigate the vast library of information and pinpoint the most relevant content for you, all in record time!
2.2 Retrieval: Casting a Wide Net#
Now that the RAG system has its information "fingerprints" stored in the vector database, it's time to find the perfect match for your query. This stage is called retrieval, and it's like having a super-intelligent librarian assist you in a massive library.
Imagine walking into a library with a question. Your friendly librarian wouldn't just point you to one specific book – they'd likely suggest a whole section or even multiple shelves based on your query. Similarly, the RAG system doesn't just search for an exact match; it casts a wide net!
Using your query and the vectors in the database, the RAG system scans for information that's most relevant. It considers synonyms, related topics, and the overall context to identify a set of documents that might hold the answer you seek.
Think of it as the librarian quickly browsing all the relevant sections based on your keywords. This initial retrieval provides the potential answers, and next, the RAG system needs to narrow it down to the absolute best match!

2.3 Similarity Matching#
The RAG system has retrieved a treasure trove of potentially helpful documents from the information ocean (thanks to the vector database!). But with so many options, how does it pinpoint the absolute best match for your question? This is where similarity matching comes in, acting like a super-powered librarian with a keen eye for detail.
Imagine you're back in the library, surrounded by a stack of books the librarian suggested might hold your answer. You wouldn't just pick one at random, right? You'd probably skim through the titles, introductions, and maybe even a few pages to see which one seems most relevant.
Similarity matching in RAG systems works on a similar principle, but instead of relying on your eyes, it uses clever techniques like cosine similarity, KNN (K-Nearest Neighbors), or Euclidean distance. Don't worry, these terms sound complex, but the basic idea is quite simple.
- Cosine similarity is like checking the "angle" between two pieces of information. Documents with a higher cosine similarity score are considered more "aligned" with your query, meaning they likely contain similar ideas and concepts.
- KNN is like asking the "nearest neighbors" for help. The system identifies a handful of documents in the database that are most similar to your query (like the closest books on the shelf) and then chooses the one that stands out as the most relevant.
- Euclidean distance is like measuring the "straight-line" distance between two points. In this case, the points represent documents in the vector database, and the system picks the one closest to your query (think of the closest book based on keywords and context).
These techniques allow the RAG system to analyze the retrieved documents and identify the one that shares the most "common ground" with your question. Remember, the system is constantly learning and improving, so over time, it becomes even more adept at finding the most relevant needle in the haystack of information. So, the next time you interact with a system powered by RAG, remember - there's a clever combination of technology and clever techniques working behind the scenes to deliver the perfect answer!

3. The Power of the LLM: Putting It All Together:
We've explored the mighty vector database for storing information and the detective-like similarity matching to find the best fit. But there's one more crucial player in the RAG system – the Large Language Model (LLM). Think of it as the master weaver, taking all the retrieved information and crafting a user-friendly response for you.
Imagine the RAG system has identified a document that's likely to hold the answer to your question. But this document might be a technical manual or a lengthy research paper – not exactly user-friendly! This is where the LLM steps in. It acts like a super-powered translator, analyzing the retrieved and matched information.
Using its vast knowledge and understanding of language, the LLM can:
- Summarize the key points from the document, giving you a concise and easy-to-understand answer.
- Generate a response tailored to your specific needs. Perhaps you need step-by-step instructions or a broader explanation – the LLM can adapt its output accordingly.
- Craft different text formats. Depending on your needs, the LLM could create an email response, a chatbot chat message, or even a formal report.
The LLM is the final touch, transforming the retrieved information into a clear, helpful, and user-friendly format that directly addresses your query. So, the next time you get a quick and informative answer from a system powered by RAG, remember - the LLM played a key role in weaving that information together for you!
4. Real-world Applications
Now that you've seen how RAG systems work their magic, let's explore how they're revolutionizing various industries:
- Customer Service: Imagine chatbots that can answer your questions accurately and efficiently, no matter how complex. RAG systems power these chatbots, allowing them to understand your query, retrieve relevant information (like FAQs or product manuals), and generate a clear and helpful response.
- Research Assistance: Researchers can leverage RAG systems to sift through mountains of data and academic papers. These systems can quickly identify relevant studies, summarize key findings, and even help researchers formulate new research questions.
- Content Creation: Struggling to write an email or a report? RAG systems can assist by analyzing relevant data and generating drafts tailored to your needs. This frees up your time and ensures your content is informative and well-written.
These are just a few examples, and the potential applications of RAG systems are vast. Imagine:
- Personalized Learning: RAG systems could personalize educational materials based on a student's individual needs and learning style.
- Medical Diagnosis: Doctors could leverage RAG systems to analyze patient data and quickly identify potential diagnoses.
- Legal Research: Lawyers could use RAG systems to find relevant case law and legal documents, streamlining the research process.
As RAG technology continues to evolve, we can expect even more exciting applications that transform the way we work, learn, and access information. The future of information retrieval is bright, and RAG systems are poised to be at the forefront!
5. Conclusion
Feeling overwhelmed by information overload? Remember, you're not alone! But fret no more, because RAG systems are here to help. We've explored the key players - the vector database for storing information efficiently, similarity matching for finding the best fit, and the LLM for weaving a user-friendly response.
Here's the takeaway: RAG systems act as intelligent assistants, sifting through vast amounts of data to deliver the information you need, fast and accurately. Whether it's answering complex customer inquiries, assisting researchers, or helping with content creation, RAG systems are transforming the way we interact with information.
The future of information retrieval is a bright one, powered by RAG technology. These systems can empower us to navigate the vast ocean of information with ease, allowing us to focus on what truly matters. So, the next time you have a question, remember - the answer might just be a RAG system away!