
by American Public Power Association
How to flatten a python list/array and which one should you use
A comprehensive review of various methods to flatten arrays and how to benchmark them
Oftentimes, when you write code you will need to reduce a nested List or a Numpy array to 1D. In other words, you want to flatten your list. Luckily, there are many ways to do this in Python. But which one should you use? In this article, we will explore various methods to achieve this task and benchmark them in order to identify which one is the most optimal method.
1. Python Lists
Here is an example of a 2D List:
list_2D = [[1,2,3],[4],[5,6],[7,8,9]]and we want to flatten it into:
list_1D = [1,2,3,4,5,6,7,8,9]1.1 List Comprehension#
This is the most Pythonic way. Even though nested list comprehension is not easy on the eye, it's a really simple method. For those who understand list comprehensions, you can skip the explanation.
list_1D = [item for sub_list in list_2D for item in sub_list]If we were to code this using nested loops we will write it like this:
list_1D = []
for sub_list in list_2D:
for item in sub_list:
list_1D.append(item)In order to convert the above code into a single liner you should break it into 3 parts:
- Outer Loop
- Inner Loop
- output expression
You start a list comprehension by opening square brackets and re-write the above steps as follows:
- Define the output expression
- Define the outer loop
- Define the inner loop
1.2 sum()#
Even though this method was designed to sum numeric values, it works with concatenating lists as well. It's a really simple solution but not an ideal one since it won't perform as well when it comes to a larger list. Overall it's an inefficient method but a quick hack. We will see the benchmark results at the end of this post. sum() is a built-in function that takes an iterable and sums the items from left to right.
Warning It is not advised to use this method in production
list_1D = sum(list_2D, [])This method takes 2 arguments. It sums the items of the iterable which is passed as the first argument and it uses the second argument as the initial value of the sum. This is an optional argument though, but since we are trying to sum nested lists, we want to start the concatenation with an empty list. So the above function is equivalent to this:
list_1D = [] + [1,2,3] + [4] + [5,6] + [7,8,9]You can imagine what will happen if we had many more sublists. This is really inefficient and not ideal for production apps. A nice metaphor to describe this is the Shlemiel the painter's algorithm written by Joel Spolsky.
In addition, if you want to check the complexity and the math of this method here is a nice read How Not to Flatten a List of Lists in Python
As it is stated on the official Python Docs there is an alternative method which is calleditertools.chain().
1.3 itertools.chain()#
Below you can find the code provided by the Python Official Documentation on how to use the chain() function.
def chain(*iterables):
# chain('ABC', 'DEF') --> A B C D E F
for it in iterables:
for element in it:
yield elementIt takes as input multiple iterables and returns the elements of each iterable one by one until all iterables are exhausted.
from itertools import chain
# [1, 2, 3, 4]
list(chain([1,2], [3,4])In our case, we only have one iterable which is a nested list. Luckily for us, there is another method designed for that which is called from_iterable().
def from_iterable(iterables):
# chain.from_iterable(['ABC', 'DEF']) --> A B C D E F
for it in iterables:
for element in it:
yield elementAnd since this function returns a chain object, we make sure we use the list constructor in order to return the flatten iterable as a list.
from itertools import chain
list_1D = list(chain.from_iterable(list_2D))1.4 functools & operator#
import functools
import operator
functools.reduce(operator.iconcat, list_2D, [])Functools is a library used mostly for higher order functions, a term used in Functional Programming. Using the reduce function, we want to pass a function as the first argument in order to reduce the iterable (passed as the second argument) to a single value. The third argument is the initialiser and this is optional.
The function to be used is the iconcat operator which basically translates to : a += b
print(operator.iconcat([1,2],[3,4]))
# [1, 2, 3, 4]So, in the end, this is equivalent to :
list_1D = [] + [1,2,3] + [4] + [5,6] + [7,8,9]This is the same result as the one on method on section 1.2 however, this is much more efficient
2. Numpy Arrays.#
Numpy arrays are one of the most efficient data structures in Python. The numpy library provides a lot of different functions that flattens the array.
import numpy as np
arr = np.array([[1, 2, 3], [3, 4,5], [6,7,8]], np.int32)2.1 flat#
list(arr.flat)2.2 flatten()#
arr.flatten().tolist()2.3 ravel()#
arr.ravel().tolist()2.4 reshape(-1)#
arr.reshape(-1).tolist()2.5 concatenate()#
np.concatenate(arr).tolist()2.6 Method comparison#
All methods do the same job, the only thing that differs is speed and memory. Some of them consume more memory because they create a new copy and others return just a view or an iterator.
The flatten() method will always return a copy whereas ravel() doesn't. Well not always, it will return a copy only if it's necessary. It only returns a view of the array, thus making it a faster approach. We can check if the function creates a copy by using the base method, which returns a value if the memory is from some other object, otherwise None.
arr = np.array([[1,2],[3,4]], np.int32)
arr_flatten = arr.flatten() # [1,2,3,4]
arr_ravel = arr.ravel() # [1,2,3,4]
arr_reshape = arr.reshape(-1) # [1,2,3,4]
arr_concatenate = np.concatenate(arr) # [1,2,3,4]
arr_flat = arr.flat # <numpy.flatiter object at 0x7fa6728d1e00>
print(arr_flatten.base) # Returns None
print(arr_concatenate.base) # Returns None
print(arr_ravel.base) # array([[1, 2], [3, 4]], dtype=int32)
print(arr_reshape.base) # array([[1, 2], [3, 4]], dtype=int32)
print(arr_flat.base) # array([[1, 2], [3, 4]], dtype=int32)All methods return the same output except arr_flat which returns an iterator
flatten()andconcatenate()methods create a new copy, hence consuming more memory- The
np.concatenate()returns the same output asflatten()but it can be used in a different context as well.flatten()is a method from thenumpy.ndarrayclass whereasconcatenatecomes fromnumpy. For example, you can concatenate multiple arrays of the same shape
3. Benchmark
In order to test the speed of each function, I designed an experiment where I generate a nested list and then run each function against it and count its time. This experiment will is repeated 100 times and I store the mean-time for each function. If you notice, the nested list is increasing its dimensions on each step so we can compare the complexity of each function over time.
import timeit
from functools import partial
def get_complexity_times(func, start, end, step, n_executions):
sample_data = []
times = []
for x in range(start, end, step):
if func.__name__.startswith('np'):
samples= np.array([list(range(10))]) * x
else:
samples = [list(range(10))] * x
# Specify the function for timing
func_timer = timeit.Timer(partial(func, samples))
t = func_timer.timeit(number=n_executions)
sample_data.append(x)
times.append(t)
return sample_data,timesYou can find the code on this collab.
3.1 Fastest method overall#
funct_times = {}
for fun in all_func:
print(fun.__name__)
_ , times = get_complexity_times(fun, 10, 1000, 10, 10)
funct_times[fun.__name__] = np.mean(times)- 100 experiments
- Every list has 10 numbers
- Initial nested list size is 10
- Every step increases the nested list size by 10 times more
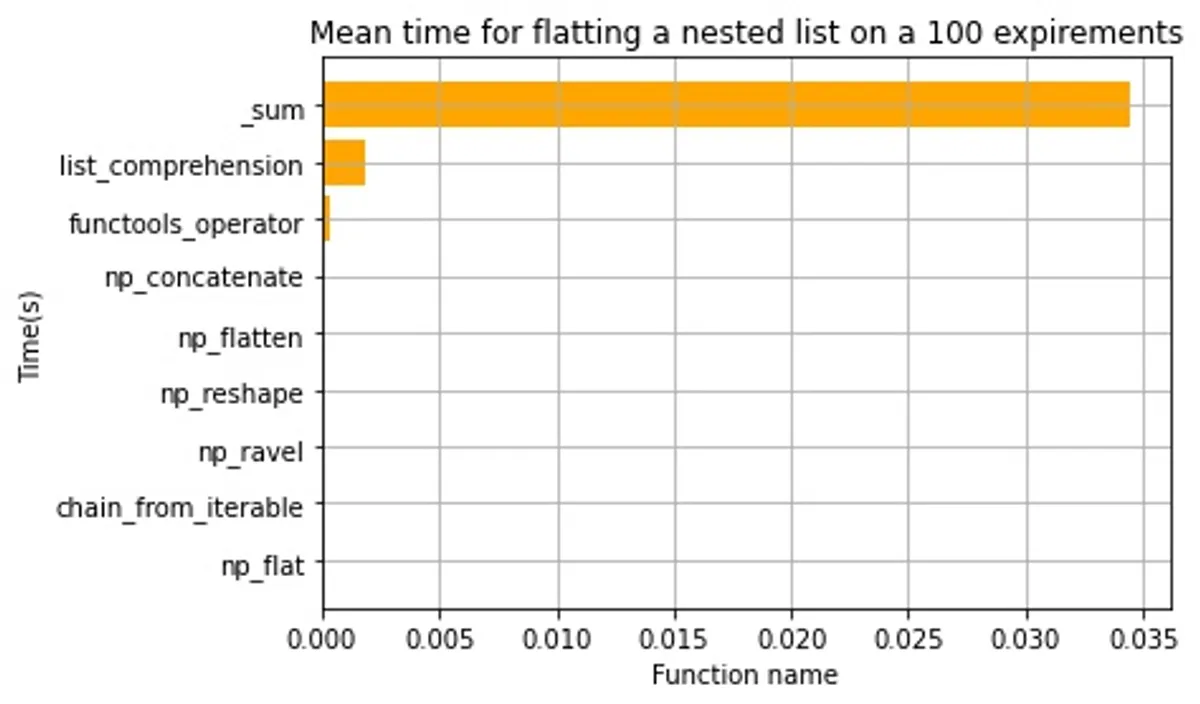
As you can see from the above plots, _sum is the worst of all and should never be used. List comprehension is slow as well. But let's remove them and have a closer look on the other methods.
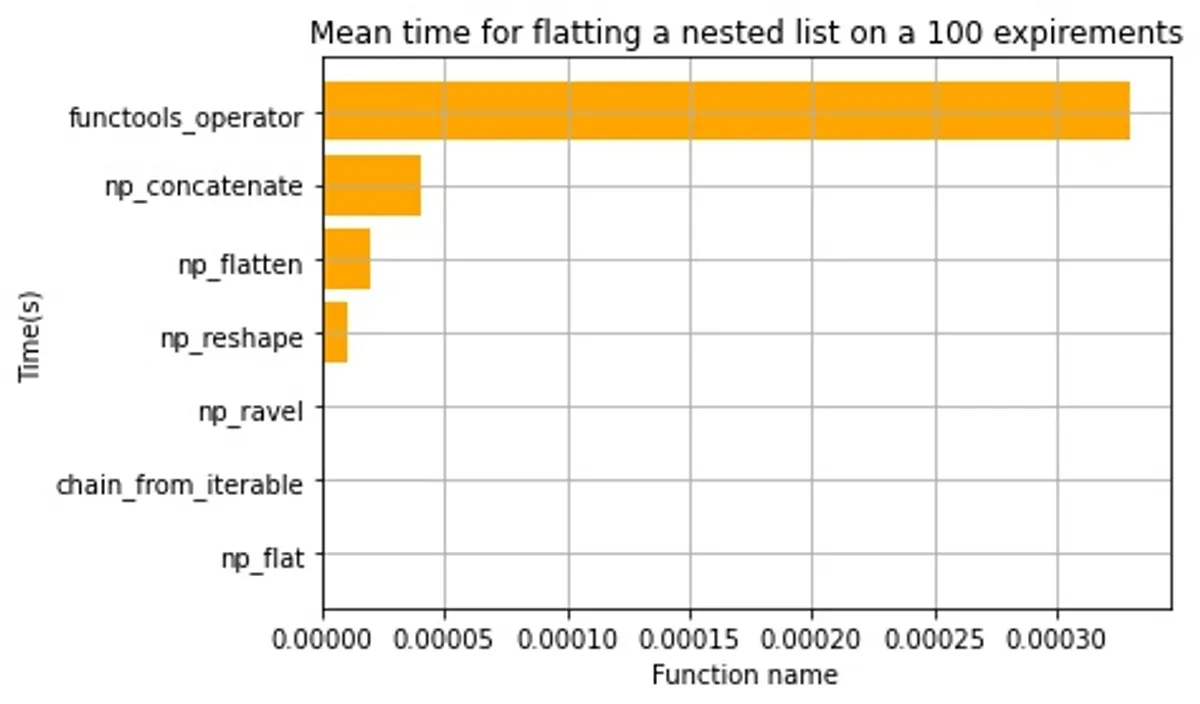
Overall all methods seem to be really fast but the fastest ones are:
.flat()chain.from_iterable().ravel()
3.2 Complexity over time while we increase the dimensions#
1000 experiments
- Every list has 10 numbers
- Initial nested list size is 10
- Every step increases the nested list size by 10 times more
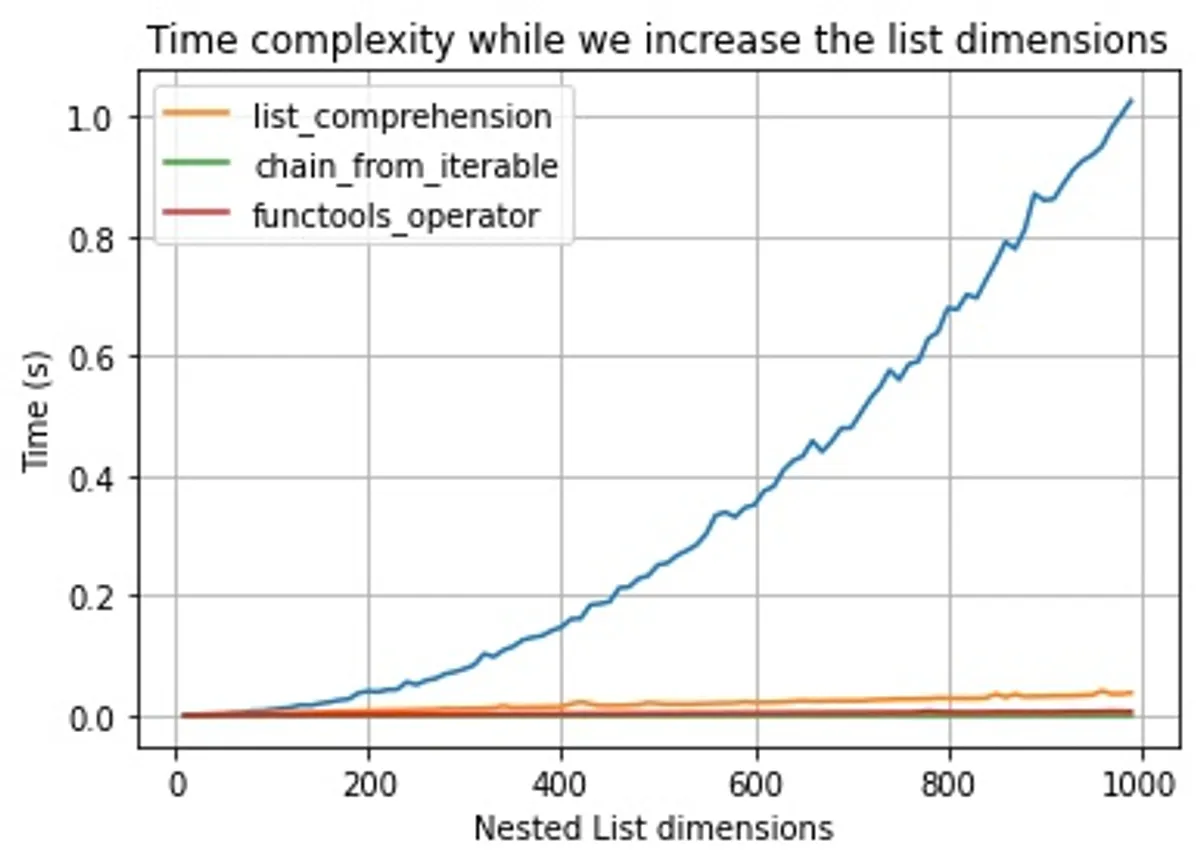
Let's isolate the non-numpy methods for a moment and examine the results. As we can see, while we increase the dimensions of the list, the _sum function becomes really slow. We can see that it even takes almost 1 second when we reach 1000 dimensions. From the curve, we can tell that the time complexity is O(n) square.
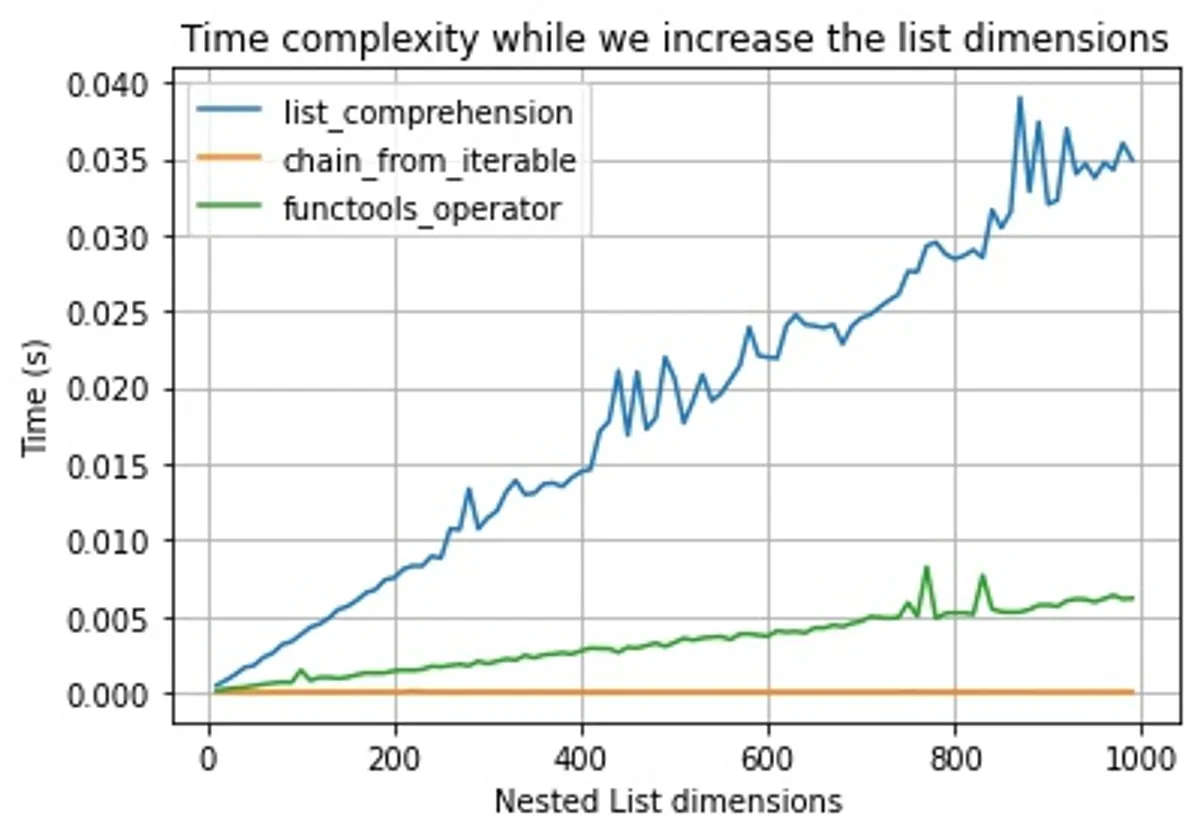
When we remove the _sum function and repeat the experiments we can tell that list_comprehension and the functools_operator is O(n), meaning the time to complete the function is dependent on the list size. So it's linearly related to the number of dimensions.
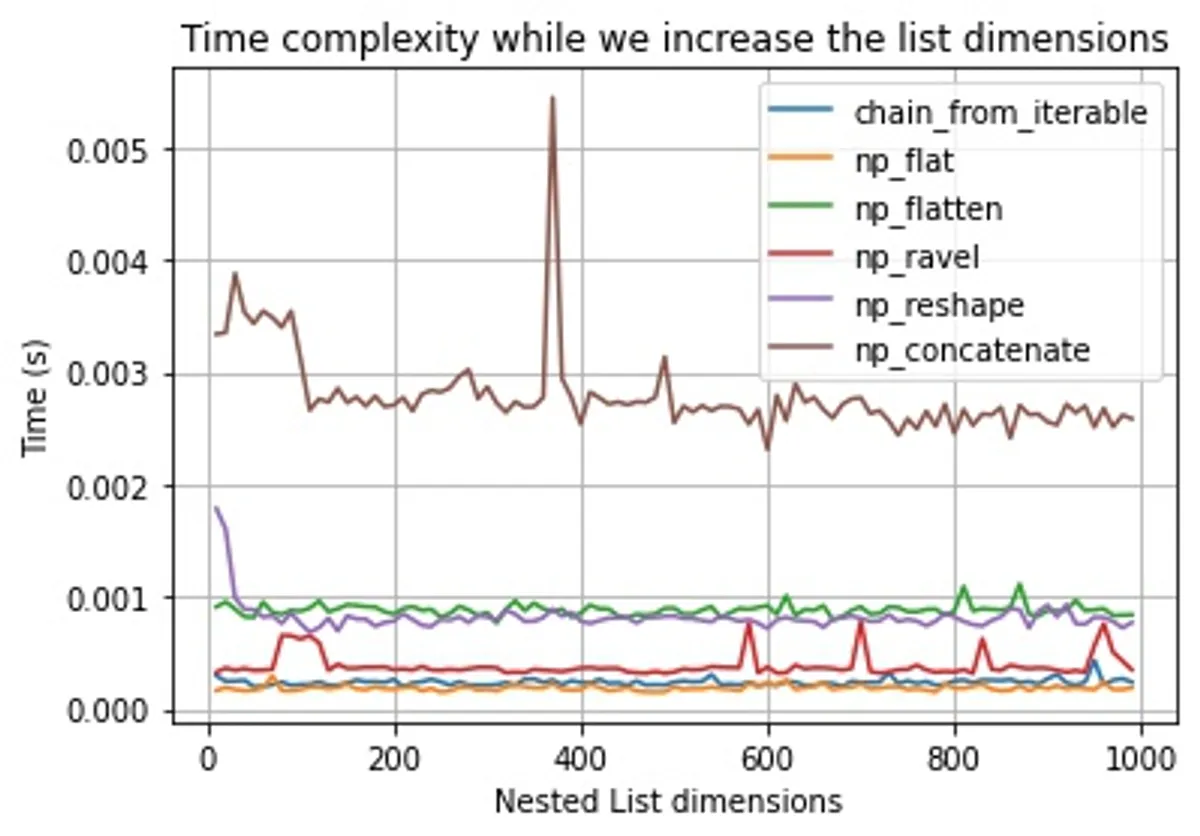
When we repeat the same experiment with the fastest methods, we can identify that their time complexity is O(1), meaning, the number of dimensions won't affect their performance.
4. Conclusion
Overall, I would conclude that I will always use the chain_from_iterable when I am working with Python Lists. Make sure you never use the _sum and the list_comprehension since they are really inefficient.
If I am working with numpy arrays:
- I would use the
flatten()method when I want a new copy and modify it's values - I would use the
reshape(-1)method when I only need a view of the array - I would use the
ravel()method if I want a view of the array but maybe modify it's values later on since ravel will create a copy automatically when it's necessary - I would use the
flatmethod if my goal was to only iterate through the array - I would only use
concatenatefunction when I have multiple arrays that I want to concatenate